Electronics News
Archive : 9 March 2026 год
Seattle-based startup ElastixAI has stepped out of stealth mode, announcing an FPGA-powered inference platform that its founders say slashes the total cost of ownership for large language model (LLM) deployments by up to 50 times compared to Nvidia GPU-based setups - while also consuming 80% less power.
ElastixAI team / founders photo or company logo
The company was founded by machine learning veterans from Apple and Meta, including CEO Mohammad Rastegari, CTO Saman Naderiparizi, and CSO Mahyar Najibi. Together the founding team holds over 24,000 academic citations. ElastixAI secured an $18 million seed round in May 2025, led by Fuse VC, to bring its vision to market.
The Problem with GPUs for AI Inference
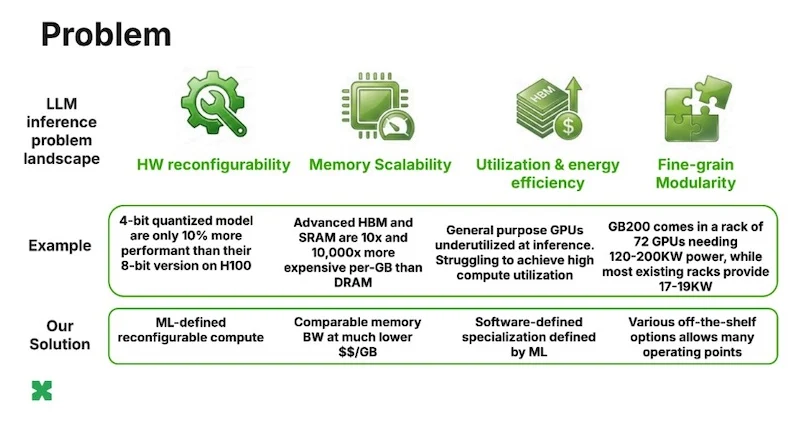
The core argument ElastixAI makes is straightforward: GPUs were designed for compute-bound tasks like model training, but LLM inference is fundamentally memory-bound. This architectural mismatch results in poor compute utilization, wasted energy, and inflated infrastructure budgets. The global AI inference market is projected to hit $255 billion by 2030, yet the hardware underpinning it remains poorly suited for the job.
Custom silicon faces another challenge - chips are designed years before they ship, meaning they inevitably trail the latest advances in machine learning. As one example, 4-bit quantization theoretically doubles performance, but on hardware without native support it may yield only a modest 10% improvement in practice.
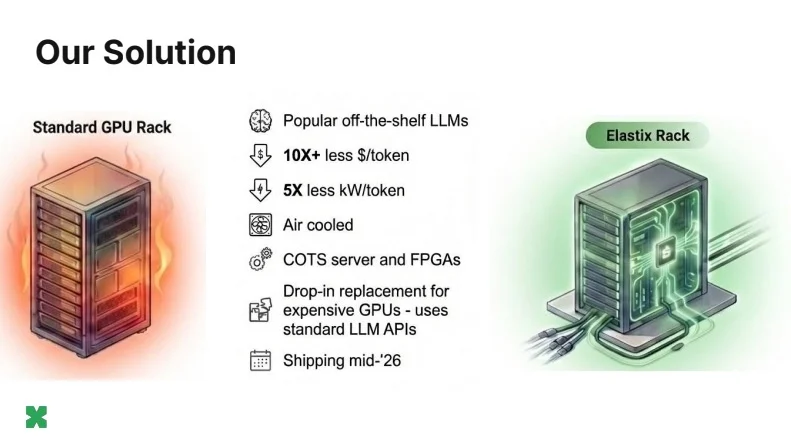
Diagram comparing GPU vs FPGA architecture for LLM inference
How ElastixAI's Approach Works
Rather than designing new chips from scratch, ElastixAI applies proprietary software-ML-hardware co-design to reprogram off-the-shelf FPGA servers into purpose-built AI inference engines. The platform activates only the circuits needed for each specific inference task, eliminating the wasted "dark silicon" that plagues general-purpose hardware.
The flagship product, called Elastix Rack, is positioned as a drop-in replacement for GPU server infrastructure. It operates within a standard 17–19 kW rack power envelope using conventional air cooling - a sharp contrast to Nvidia's GB200 NVL72, which demands between 120 and 200 kW and requires specialized liquid-cooling infrastructure that most existing data centers simply cannot support.
Seamless Migration from GPU Workflows
Migration from existing GPU setups is handled via a vLLM plug-in that replaces the Nvidia CUDA backend while keeping the front-end OpenAI-compatible API intact. This means operators can switch infrastructure without modifying their application stack. ElastixAI also plans to open its model conversion tooling to the broader ML research community - a strategy the team explicitly compares to how Nvidia cultivated the CUDA developer ecosystem.
On memory, ElastixAI optimizes for cost-per-bandwidth and cost-per-capacity rather than chasing the most expensive memory tiers. By using ML-defined software specialization, it extracts high-bandwidth performance from cost-effective DDR and HBM running on commercial FPGA hardware.
Looking Ahead
First shipments of the Elastix Rack are planned for mid-2026. The company's approach reflects a broader bet that in a world where ML architectures evolve faster than silicon development cycles, reconfigurable hardware