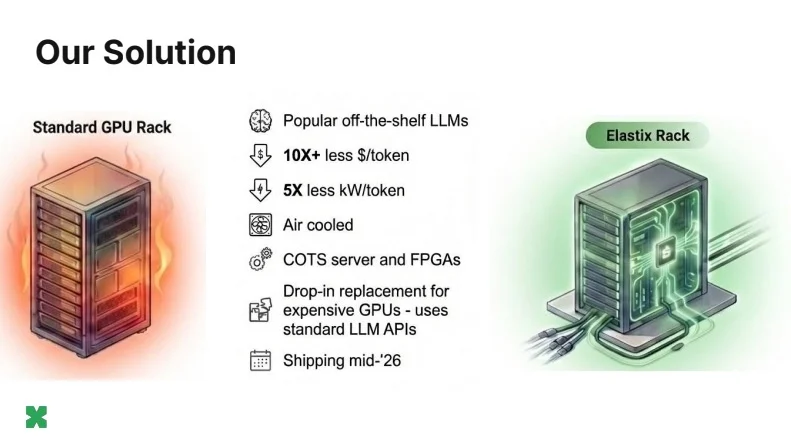
Сиэтлский стартап ElastixAI вышел из стелс-режима, объявив о создании платформы инференса на базе FPGA. По заявлению основателей, она снижает совокупную стоимость владения (TCO) при развёртывании больших языковых моделей (LLM) до 50 раз по сравнению с решениями на GPU Nvidia, потребляя при этом на 80% меньше электроэнергии.
Компанию основали специалисты по машинному обучению из Apple и Meta: генеральный директор Мохаммад Растегари, технический директор Саман Надерипаризи и директор по науке Махьяр Наджиби. Совокупное число академических цитирований команды превышает 24 000. В мае 2025 года ElastixAI привлекла посевные инвестиции в размере $18 млн под руководством Fuse VC.
Почему GPU плохо подходят для инференса
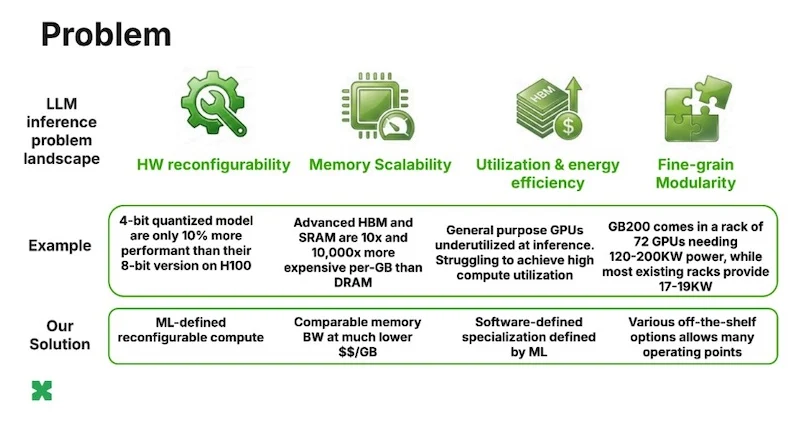
Центральный тезис ElastixAI прост: GPU создавались для вычислительно-ёмких задач вроде обучения моделей, тогда как инференс LLM по своей природе ограничен пропускной способностью памяти. Это архитектурное несоответствие оборачивается низкой утилизацией вычислительных ресурсов, избыточным энергопотреблением и раздутыми бюджетами на инфраструктуру. К 2030 году мировой рынок инференса ИИ, по прогнозам, достигнет $255 млрд — однако аппаратная база по-прежнему не оптимальна для этой задачи.
Заказные чипы сталкиваются с отдельной проблемой: их проектируют за годы до выхода на рынок, и к моменту поставки они неизбежно отстают от актуальных достижений в области машинного обучения. Например, 4-битное квантование теоретически удваивает производительность, однако на оборудовании без нативной поддержки прирост на практике составляет лишь около 10%.
Как работает подход ElastixAI
Вместо разработки новых чипов с нуля ElastixAI применяет фирменный метод совместного проектирования программного обеспечения, алгоритмов ML и аппаратуры — перепрограммируя серийные FPGA-серверы в специализированные движки инференса. Платформа активирует только те схемы, которые необходимы для конкретной задачи, устраняя потери на «тёмный кремний», характерные для универсального оборудования.
Флагманский продукт — Elastix Rack — позиционируется как прямая замена GPU-серверной инфраструктуре. Он работает в стандартной стойке с энергопотреблением 17–19 кВт и обычным воздушным охлаждением. Для сравнения: Nvidia GB200 NVL72 требует от 120 до 200 кВт и специализированной жидкостной системы охлаждения, которой большинство существующих ЦОД просто не располагает.
Простой переход с GPU-инфраструктуры
Миграция с существующих GPU-решений осуществляется через плагин vLLM, заменяющий бэкенд Nvidia CUDA при сохранении совместимого с OpenAI API на фронтенде. Это позволяет операторам менять инфраструктуру без изменения прикладного стека. ElastixAI также планирует открыть инструменты конвертации моделей для широкого сообщества ML-разработчиков — по аналогии с тем, как Nvidia формировала экосистему CUDA.
В части памяти компания оптимизирует соотношение стоимости и пропускной способности, а не гонится за самыми дорогими типами памяти. За счёт программной специализации на основе ML платформа извлекает высокопроизводительную работу с памятью из экономичных модулей DDR и HBM на серийном FPGA-оборудовании.
Планы на будущее
Первые поставки Elastix Rack запланированы на середину 2026 года. Подход компании отражает более широкую ставку: в мире, где архитектуры ML развиваются быстрее, чем циклы разработки кремния, реконфигурируемое оборудование со временем опередит специализированные чипы с фиксированной функциональностью.
Растегари, ранее основавший Xnor.ai — приобретённую Apple в 2020 году приблизительно за $200 млн — и впоследствии руководивший оптимизацией инференса модели Llama 405B в Meta, сформулировал миссию компании прямолинейно: отрасль сейчас упускает на порядок больше производительности из-за того, что аппаратное обеспечение не успевает за прогрессом в машинном обучении.